Loading...
Gadgets
Health
Ai
Finance
Space
Society
Military
Nature
Science
Tech
History
Science
Daily
Searching article... Please, wait 5 second for reloading content
Awesome last month
Croatia gets French fighter jets in major arms purchase
Node.js 22 arrives, backs ECMAScript modules
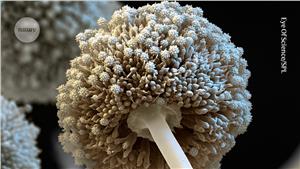
Garden-variety fungus is an expert at environmental clean-ups
Unlocking New Levels of Accuracy With Advanced Timing Chips
Boeing CEO Message to Employees: Taking Action to Strengthen Safety and Quality
Can an online library of classic video games ever be legal?
Millions of IPs remain infected by USB worm years after its creators left it for dead